In this lesson, you will distinguish between the hierarchical and network data models created in the 1970s. Specifically, this lesson will cover:
1. Hierarchical Model
The hierarchical model was one of the first widely used data models in the 1970s. It was created to manage large amounts of data for complex manufacturing projects.
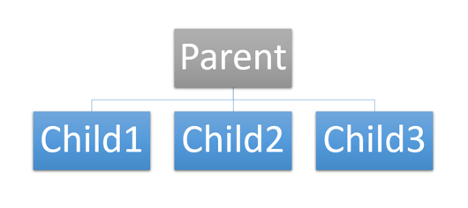
The logical structure of the hierarchical model looks like an upside-down tree, where the model contains levels or segments. A segment in the hierarchical model is similar to a file system’s record type. In a hierarchy, the higher layer is the “parent” of the “child,” or the segment below it. The hierarchical model is basically a set of one-to-many relationships, where each parent segment can have many children, but each child segment can only have one parent.
|
Advantages of the Hierarchical Model
|
Disadvantages of the Hierarchical Model
|
- It is easy to understand and visualize.
- It is efficient for storing and retrieving data that is naturally hierarchical.
- It is relatively easy to implement.
|
- It is not as flexible as other data models.
- It can be difficult to update data in the model.
- It is not as scalable as other data models.
|
Here are some examples of hierarchical databases that you might still run into in the workplace.
- IMS (Information Management System) was one of the first hierarchical databases developed. It was developed by IBM in the 1960s and was widely used in the mainframe environment. This system helped us get to the moon.
- Hierarchic Data Store (HDS) was another early hierarchical database developed by IBM. It was designed for use in the distributed environment.
- Informix is a hierarchical database that is still in use today. It is designed for use in the enterprise environment.
-
- Segment
- A structured set of data elements.
- Hierarchical Model
- A database model that consists of a series of one-to-many relationships, with each parent item having one or more child items.
2. Network Model
The network model was created in the 1960s to help deal with some of the issues of complex data relationships that could not be represented in the hierarchical model. It was designed to help improve performance in the database and create a database standard.
The network model represents data as a network of interconnected records. It uses pointers to establish relationships between data elements, allowing for more complex and flexible data structures compared to the hierarchical model. Like the hierarchical model, the network model also used the one-to-many relationship, but a record in the network model can have more than one parent. Even though network data models are no longer used today, a lot of the key concepts that came from the network model are still used. These include the schema, subschema, data manipulation language, and data definition language. Network models are useful for non-hierarchical data, such as company organizational charts and family trees that may have multiple parents or supervisors for a single person.
As information needs grew, the network model became a bit too cumbersome. Because there were no built-in query capabilities, programmers had to create the code to run even the simplest reports. The commands needed to query a network model database were a lot more complex than the SQL commands that you will be using to query the data in our relational database. In addition, if there was any change in the database structure, it would create problems across all of the applications that accessed the data, as they heavily depended on the data model structure to match.
|
Advantages of the Network Model
|
Disadvantages of the Network Model
|
- It is more flexible than the hierarchical model.
- It can represent complex relationships between data.
- It is relatively easy to implement.
|
- It is not as easy to understand and visualize as the hierarchical model.
- It can be difficult to update data in the model.
- It is not as scalable as the relational model.
|
Here are some examples of network databases you might still find in the workplace:
- IDMS (Integrated Data Management System) was one of the first network databases developed. Cullinane Corporation developed it in the 1970s, and it was widely used in the mainframe environment. There are still companies that use this system.
- ICL DMS was another early network database developed by ICL in the 1970s. It was designed for use in the distributed environment.
- Adabas is a network database that is still in use today. It is designed for use in the enterprise environment.
Some new concepts were introduced in the network model that were foundational to later models that came along, including the first steps toward a programming language like SQL. Some of these new concepts were:
- The schema, which is the conceptual organization of the database. This is the view seen by a database administrator, who is able to see the complete database.
- The subschema, which is the part of the database that the applications can see, rather than the entire database.
-
Data manipulation language (DML) represents the commands used to work with the data. In modern relational databases, this includes SQL statements such as SELECT, UPDATE, INSERT, and DELETE.
-
Data definition language (DDL) allows database administrators to create and remove the various schema components in the database. In modern relational databases, this includes the SQL statements CREATE, ALTER, and DROP.
-
- Data Definition Language (DDL)
- Commands that create and remove schema components in a database.
- Data Manipulation Language (DML)
- Commands that allow interaction with the data in a database.
- Network Model
- A database model that represents data as a network of interconnected records with pointers used to establish relationships between data elements.
- Schema
- The conceptual organization of an entire database.
- Subschema
- The part of a database that applications interact with.
In this lesson, you learned that the second generation of data models included the hierarchical and network models. These models offered more sophistication than basic file systems but also added cumbersome complexity to the task of tracking and finding files.